My findings after implementing the DNS query without any library. This domain name system is nicely tucked away in the network drawers, so you don’t even notice it. Nonetheless, it is used by everyone on the internet multiple times a day.
Also called the “phone book of the internet”, DNS helps translate from human-readable hostnames (example.com) to computer-friendly IP addresses (23.192.228.80).
While learning, I put together a toy project, rbdig, written in Ruby, as I’m more comfortable with this language. Due to refactoring, the project’s code might not exactly match the code snippets presented here.
The steps I’ll describe:
- Building the DNS request
- Creating a socket and sending the DNS request
- Receiving and parsing the DNS reply
- Handling the recursive queries myself
I guided myself using this official document, RFC1035, to construct the DNS request and parse the response.
Step 1: Building the DNS request
The DNS request has two parts:
- header (12 bytes)
- question (variable length)
I wanted to how this is done by other tools. With the help of Netcat, I captured a DNS lookup from dig. I also used Wireshark to view the UDP packet as it does a good job of representing network packets.
# Start a listener on port 2020 (saving the output to a file)
nc -u -l 2020 > dns_lookup.txt
# Send a dig request to that port
dig +retry=0 -p 2020 @127.0.0.1 +noedns example.com
# Tip: you can use nc to forward the request to a DNS server (ex: Cloudflare's)
nc -u 1.1.1.1 53 < dns_lookup.txt > resp_dns_lookup.txt
This is the whole request sent by dig (as hex bytes):
840f01200001000000000000076578616d706c6503636f6d0000010001
But what does it all mean?
The first 12 bytes are the header: 840f01200001000000000000. I spread the method handling so that it includes comments for each component.
The header is described in section 4.1.1. You can find further info on what each means.
def query_header
query_id = "\x84\x0f" # 2 random bytes. When we get the response, the same bytes should be included
flags = "\x01\x00" # the standard flag
qd_count = "\x00\x01" # the # of entries in the question section
an_count = "\x00\x00" # the # of resource records in the answer session
ns_count = "\x00\x00" # the # of name server resource records (in authority records section)
ar_count = "\x00\x00" # the # of resource records
query_id + flags + qd_count + an_count + ns_count + ar_count
end
Now that the header is handled, I could move to the next section.
The question section is made of:
- question name - the actual domain name we’re looking for
- query type - the type of record we’re looking for (ex: “A” for IPv4 record)
- query class - the class of record we’re looking for (ex: “IN” for the INternet)
The more complex part was building the question name. DNS has a format for encoding domain names. It follows a sequence of labels. Each label is made of a length octet + that number of octets. The domain name is terminated with a null label \x00.
A domain name as www.example.com becomes 3www7example3com0. My code for this:
def encode_domain(domain)
enc = domain.strip.split('.').map { |s| [s.length].pack("C") + s }.join
enc + "\x00"
end
Here is a screenshot of the request in Wireshark. If you want to reproduce this, set Wireshark to listen to the loopback interface and filter for the right udp.port.
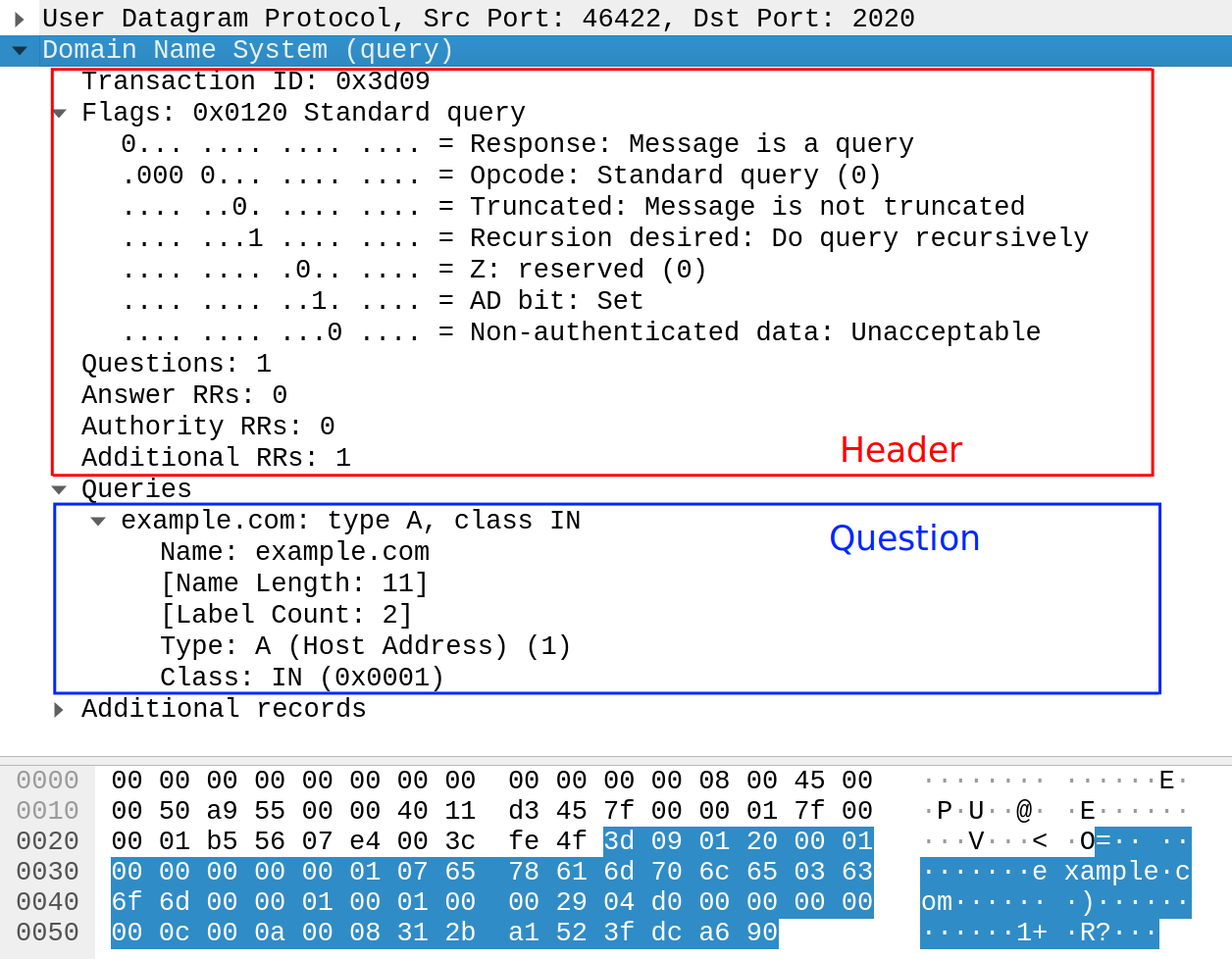
I put all the encoding logic in the DNSQuery class.
Step 2: Creating a socket and sending the DNS request
I’ll not get into details here. The idea is to get this request out and listen to a response from the DNS server.
I created a UDP socket for this and wrapped everything in the connect method.
def connect(message, server = '1.1.1.1', port = 53)
socket = UDPSocket.new
socket.send(message, 0, server, port)
response, _ = socket.recvfrom(512) # RFC1035 specifies a 512 octets size limit for UDP messages
socket.close
response
end
Step 3: Receiving and parsing the DNS reply
The DNS server will send back the response, which might or might not include the answer (the IPv4 address in our case). After receiving the response, I validated it has the same query_id as the request, and I was starting to parse it. Basically, I reversed the steps I used when building the request, and parsing the header and question sections. But, in addition, the DNS response might include 3 more sections, each including zero or more Resource Records (RRs):
- Answers - the answer we’re looking for
- Authorities (NS records) - when a nameserver doesn’t have the answer, it will redirect you to other servers
- Additional - also when a nameserver doesn’t have the answer, but it includes the IPv4 address of those servers that might have the answer. This section could contain other data, but that’s out of the scope of this article. These Resource Records (RRs) all have the same format.
Here is a visual of how the DNS response is structured (source: RFC1035):
+---------------------+
| Header |
+---------------------+
| Question | # the question for the name server
+---------------------+
| Answer | # RRs with the answer
+---------------------+
| Authority | # RRs pointing toward authority servers
+---------------------+
| Additional | # RRs holding additional information
+---------------------+
A word on Reader
The DNS response will be a string of bytes, I needed to go over it while parsing. To keep track of where I was in the string, I created the Reader class. This gets initialized with a string. It can read a specific number of bytes from that string while keeping a pointer of the position I’m in the string.
A brief example:
r = Reader.new("\x00\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0A".b)
r.pos # => 0
r.read(2) # => "\x00\x01"
r.pos # => 2
Ruby has the StringIO class, which does this and more. But for this project, I wanted to implement the functionality I needed.
The parsing class
I created the DNSResponse class responsible for handling the response. It accepts the raw response and initiates an instance of Reader with that bytes string:
class DNSResponse
attr_reader :header, :body, :answers, :authorities, :additional
def initialize(dns_reply)
@buffer = Reader.new(dns_reply.b)
@header = parse_header
@body = parse_body
@answers = parse_resource_records(@header[:an_count])
@authorities = parse_resource_records(@header[:ns_count])
@additional = parse_resource_records(@header[:ar_count])
end
def parse_header
query_id, flags, qd_count, an_count, ns_count, ar_count = @buffer.read(12).unpack('n6')
{ query_id:, flags:, qd_count:, an_count:, ns_count:, ar_count: }
end
def parse_body
question = extract_domain_name(@buffer)
q_type = @buffer.read(2).unpack('n').first
q_class = @buffer.read(2).unpack('n').first
{ question:, q_type:, q_class: }
end
[...]
Extracting the domain name was maybe the most complex part. Up until now, it is straightforward, I could transform from \x07example\x03com\x00 to example.com and that would suffice.
However, I encountered some exceptions while I progressed to parsing the RR sections. Here is the method which does the parsing. It is neat that all RRs I care about for now have the same format.
# class DNSResponse
def parse_resource_records(num_records)
# It returns an array of records if any
num_records.times.collect do
rr_name = extract_domain_name(@buffer) # A domain name to which this RR belongs
rr_type, rr_class = @buffer.read(4).unpack('n2') # The type & class of this record
ttl = @buffer.read(4).unpack('N').first # Time-to-live for this record (how long it should be cached)
rr_data_length = @buffer.read(2).unpack('n').first # The length (bytes) of the rr_data field
# Data describing the resource, variable length depending on the type of resource.
# Ex: for TYPE='A' and CLASS='IN', the data = IPv4 address (4 bytes length)
rr_data = extract_record_data(@buffer, rr_type, rr_data_length)
{ rr_name:, rr_type:, rr_class:, ttl:, rr_data_length:, rr_data: }
end
end
# Sample RR
# {:rr_name=>"com", :rr_type=>2, :rr_class=>1, :ttl=>172800, :rr_data_length=>20, :rr_data=>"a.gtld-servers.net"}
Handling DNS compression and preventing loops
When the server encodes the DNS message, there might be repeated domain names. In order to keep the message size to a minimum, the domain system uses a compression scheme. If a certain value appeared beforehand in the message, instead of repeating the same name, it places a pointer to a previous occurrence of the same name. How does this look in practice?
If we search for example.com, the server might not have the answer, so it directs you to various .com TLD servers. It lists NS records, so, when it encodes the rr_name field, instead of repeating com, it points you to the question section which has the com value.
How does the pointer… points?
A domain label can have a maximum length of 63 character, or 00111111. Notice those two leading zeros? They can be used to differentiate a label from a pointer. The octet that points will have the first two bits set to one 11000000 (which is \xc0 in hex, 192 in decimal). The byte values starting with 01 & 10 are reserved for future use.
Then, it indicates the offset, the position where we can find the label. This is the remaining 14 bits.
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| 1 1| OFFSET |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
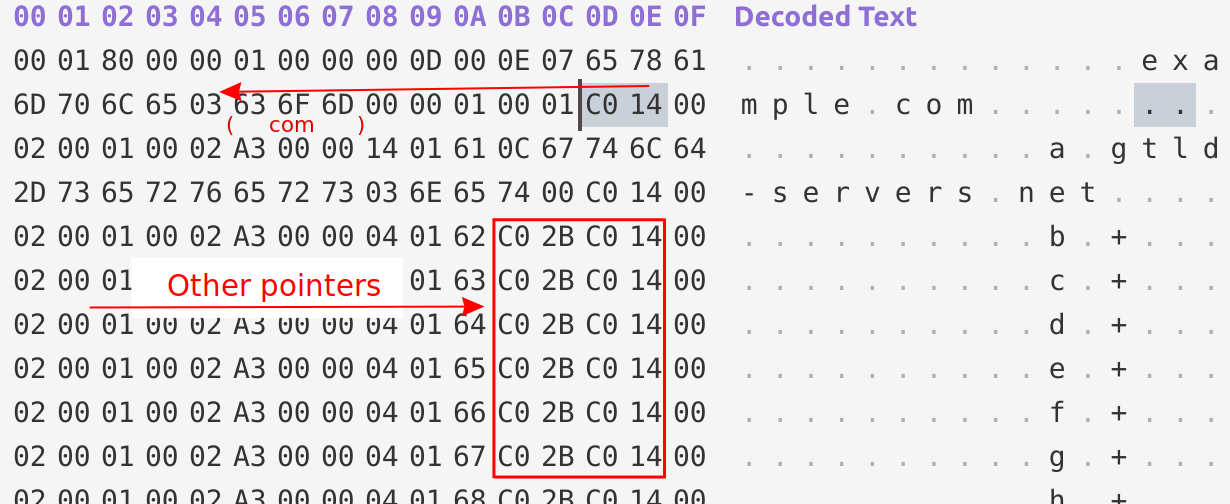
Here is a reply from a DNS root server answering to example.com. The first pointer in the response is highlighted (\xc0\x14). We start by reading this and notice the first byte is (\xc0) indicating a pointer. We would read the rest of the byte and sum it to the second byte to see where it points to, \x14 is 20 in decimal. So we would need to go back to position 20 and read the label from there. The label is com in this example.
Notice also the other highlighted pointers. This shows how DNS compression saved message estate by preventing repetition.
Section 4.1.4 of the RFC1035 describes the DNS compression.
Here is the code for extracting the domain name and handling DNS compression:
# class DNSResponse
def extract_domain_name(buffer)
domain_labels = []
loop do
read_length = buffer.read(1).bytes.first
break if read_length == 0
if read_length == 0b11000000
# Byte is pointer (DNS compression)
pointing_to = buffer.read(1).bytes.first
current_pos = buffer.pos
buffer.pos = pointing_to
domain_labels << extract_domain_name(buffer)
buffer.pos = current_pos
break
else
# Normal case, read the label as it is
domain_labels << buffer.read(read_length)
end
end
domain_labels.join(".")
end
Preventing an infinite loop
When RFC1035 was created, it didn’t warn about any harmful implementations of DNS compression. If we blindly follow the pointer without validating its value, we expose ourselves to memory corruption bugs and buffer overruns. This open the gates to possible DoS and even RCE attacks.
For example, if the pointer is set to \xff\xff, the offset value will be 16383, way out of the bounds of a DNS packet.
The same is for decoding the domain name, we should make sure the length label’s value is no more than 63, so we prevent reading from other parts of memory.
Or if a pointer will offset to the current position minus one, to the pointer itself, that is, it will result in an infinite loop.
Here is the method, updated for handling these edge cases.
A simple query
Up until this point, I could do this basic query. Notice we’re asking Cloudflare’s DNS resolver, which will do all the work, sending subsequent queries to find the domain address (if not already cached).
domain = "example.com"
dns_resolver = "1.1.1.1"
query_id = "\x00\x01"
msg = DNSQuery.new(query_id).query_message(domain)
socket_response = connect(msg, dns_resolver)
raise "Invalid response: query ID mismatch." if socket_response[0..1] != query_id
dns_response = DNSResponse.new(socket_response).parse
if dns_response.answers.any?
puts dns_response.answers.first[:rr_data]
else
puts "Answer not found for #{domain}."
end
# => 23.215.0.138
4. No answer on the first try? (looping and querying NS servers)
I wanted to see the whole DNS process, and until now, my request flags have the Recursive Desired (RD) bit set to one. This means, I rely on the DNS server to handle any further queries until it finds the answer (if it supports RD). The conversation will be:
me: Can you tell me the IP address for "example.com"?
DNS server: I don't have it, but I'll ask other servers and come back with an answer.
If setting RD to zero, the discussion will be:
me: Can you tell me the IP address for "example.com"?
DNS server: I don't have it, but here is a list of servers who might know.
The new flag will then be \x00\x00, and I’ll also switch to querying one of the root servers (ex: l.root-servers.net at 199.7.83.42).
This new modification means I need to send more queries if the first one doesn’t return an answer. I’ll use a loop and always check the answers section of the DNS response. If no answers, the DNS server will hopefully return a list of records (in the additional section) with their own IP addresses. I will use it to query the next servers, which are likely to have the answer.
In some cases, the response has no additional records, but instead, the authorities section contains a list of authoritative nameservers. They are presented with their domain names instead of the IP address, which requires me to find out their own IP address before querying them.
def lookup(domain)
nameserver = '199.7.83.42' # l.root-servers.net
max_lookups = 10
max_lookups.times do
puts "Querying #{nameserver} for #{domain}"
query_id = [rand(65_535)].pack('n')
msg = DNSQuery.new(query_id).query_message(domain)
socket_response = connect(msg, nameserver)
raise "Invalid response: query ID mismatch." if socket_response[0..1] != query_id
dns_response = DNSResponse.new(socket_response).parse
if dns_response.answers.any?
# The query found an answer
return dns_response.answers[0][:rr_data]
end
if dns_response.additional.any?
# No answer, try querying these additional resources
nameserver = dns_response.additional[0][:rr_data]
next
end
if dns_response.authorities.any?
# No answer, but here is the authority servers that might know the answer
ns_name = dns_response.authorities[0][:rr_data] # An example: a.iana-servers.net
# Lookup authority server's IP address
nameserver = lookup(ns_name)
next
end
end
raise "Max lookups reached."
end
result = lookup('example.com')
puts "\nAnswer: #{result}"
Querying 199.7.83.42 for example.com
Querying 192.5.6.30 for example.com
Querying 199.7.83.42 for a.iana-servers.net
Querying 192.5.6.30 for a.iana-servers.net
Querying 199.43.135.53 for a.iana-servers.net
Querying 199.43.135.53 for example.com
Answer: 23.192.228.80
In the latest implementation of my project, the same can be achieved with the command:
./dig.rb -t -s example.com
This was the implementation of a recursive, and then iterative DNS query, from scratch. There are infinite improvements and features that can be added this project, like:
- support querying other record types, and other record classes
- DNSSEC
- ability to resolve a list of domain names, instead of a single domain
- support for reverse DNS lookups
- etc.
Just some features I might add in the future.